Puoi anche consultare:
- Il nostro paper su Minerva per una panoramica tecnica dei nostri large language model.
- Il nostro paper su ITA-Bench per una panoramica tecnica di ITA-Bench, la nostra suite di valutazione per gli LLM italiani.
I Large Language Model (LLM) stanno rivoluzionando il modo in cui interagiamo con la tecnologia. Questi modelli eccellono in attività come riassumere notizie, tradurre testi e fornire risposte in modo naturale e conversazionale. Tuttavia, la maggior parte degli LLM è addestrata prevalentemente in inglese, il che significa che altre lingue, come l'italiano, ricevono spesso meno attenzione. È qui che entra in gioco Minerva: una famiglia di LLM addestrata interamente da zero anche su testi italiani.
Minerva si distingue come un progetto diverso, la prima iniziativa a sviluppare LLM principalmente per la lingua italiana, indipendentemente da modelli preesistenti addestrati in inglese. A differenza di altri modelli che adattano una base inglese per accogliere l'italiano, abbiamo progettato Minerva con l'italiano come obiettivo centrale fin dall'inizio. Questo approccio ci ha permesso di calibrare i nostri modelli sulle caratteristiche specifiche della lingua italiana, tra cui il suo ricco vocabolario, la sintassi complessa e le sfumature culturali, aspetti in cui i modelli centrati sull'inglese spesso risultano carenti.
Puoi anche consultare:
È importante comprendere anche i limiti dei nostri modelli Minerva. Per quanto potenti e versatili, sono ben lontani dall'essere perfetti. Possono ancora manifestare bias, generare risposte errate o inappropriate, o avere difficoltà con determinate attività. Lavoriamo continuamente per migliorare Minerva e affrontare queste sfide, ma è essenziale utilizzare questi modelli in modo responsabile e valutare criticamente i loro output.
È importante notare che Minerva è un progetto di ricerca e si basa su fonti disponibili e documentate. I modelli non forniscono sempre risposte perfette e possono talvolta generare risposte errate o inappropriate. Soprattutto, Minerva è principalmente un modello linguistico e, sebbene abbiamo lavorato sul suo aspetto conversazionale, qualsiasi confronto con chatbot commerciali, come ChatGPT o Claude, va preso con cautela. Questi modelli sono addestrati con un insieme molto più ampio di dati non documentati e contano centinaia di miliardi di parametri.
La maggior parte degli LLM è addestrata principalmente su testi in inglese, il che spinge naturalmente questi modelli verso bias centrati sull'inglese, con un impatto sulle loro prestazioni quando trattano altre lingue. Il vocabolario, ovvero le "parole" che questi modelli possono utilizzare per leggere un input e generare un output, è ottimizzato per l'inglese, il che significa che, quando hanno a che fare con l'italiano, spesso incontrano difficoltà. Infatti, nei modelli esistenti, le parole italiane vengono suddivise in più frammenti rispetto a una parola inglese, con conseguenti tempi di inferenza più lunghi e una minore fluidità nel generare testo italiano dal suono naturale. Con Minerva abbiamo superato questi limiti costruendo un modello progettato per gestire l'italiano in modo efficace ed efficiente. Questo significa che i modelli Minerva generano testo più naturale e culturalmente accurato in italiano, offrendo un vantaggio significativo rispetto agli LLM esistenti centrati sull'inglese (es. Mistral-7B-v0.2), agli LLM multilingue (es. Llama-3.1) e agli LLM adattati da modelli centrati sull'inglese (es. Anita, Llamantino-2 e Maestrale, tra gli altri).
L'importanza di Minerva va oltre il semplice essere un modello linguistico per l'italiano. Affronta anche questioni più ampie nella ricerca sull'Intelligenza Artificiale. Concentrandoci su una lingua diversa dall'inglese, abbiamo compiuto un passo verso un'IA più inclusiva e in grado di servire comunità diverse. I dati utilizzati per addestrare Minerva sono interamente open-source, consentendo ad altri ricercatori e sviluppatori di basarsi sul nostro lavoro. Questa apertura è in contrasto con molti dei large language model prodotti oggi, dove i dati di addestramento sono tenuti segreti (questo vale non solo per i modelli chiusi come ChatGPT o Claude, ma anche per quelli a pesi aperti, come tutti i modelli basati su Llama e Mistral). Inoltre, Minerva è progettata per minimizzare i bias che potrebbero esistere in altri modelli addestrati principalmente in inglese. Questo è cruciale, perché i bias culturali nei modelli linguistici possono portare a inesattezze o risposte inappropriate. Creando un modello che comprende profondamente la cultura e la lingua italiana, contribuiamo a un panorama dell'IA più equo.
Il progetto Minerva non è stato un'impresa semplice. Abbiamo iniziato addestrando una serie di modelli "base", che vanno da 350 milioni a 7 miliardi di parametri. Un modello base è un large language model addestrato su un'ampia varietà di dati testuali per stimare la probabilità di una parola dato il suo contesto. Questo processo è spesso noto come preaddestramento, poiché il modello si limita ad apprendere la struttura della lingua senza alcuna attività specifica in mente. Più grande è il modello, più parametri possiede, il che gli consente di catturare pattern più complessi nei dati e di generare risposte più accurate.
Per costruire i nostri modelli base, abbiamo raccolto e curato un'enorme quantità di testo italiano per addestrare i modelli, includendo fonti come Wikipedia, articoli di giornale, libri, documenti legali e contenuti del Web. Le nostre principali fonti di testo per i contenuti del Web sono RedPajama v2 e CulturaX, due raccolte aperte di dati ottenuti da Common Crawl. La quantità totale di token che Minerva vede durante il suo addestramento è di oltre 2.000.000.000.000 (2 trilioni) di token, l'equivalente di oltre 15 milioni di libri, metà in italiano e metà in inglese. L'obiettivo era esporre il modello a un'ampia varietà di usi della lingua, dall'enciclopedico al colloquiale, catturando la ricchezza dell'italiano così come viene parlato e scritto in vari contesti. Abbiamo addestrato quattro diverse versioni di Minerva, da un modello più piccolo con 350 milioni di parametri fino a modelli più grandi con 1 miliardo, 3 miliardi e fino a 7 miliardi di parametri. I parametri sono essenzialmente i mattoni di questi modelli che li aiutano a comprendere e generare il linguaggio. Creando versioni diverse, il nostro obiettivo era fornire modelli non solo potenti ma anche accessibili a vari tipi di utenti e applicazioni, da chi ha bisogno di un modello leggero a chi desidera le capacità più avanzate.
I dati di addestramento di Minerva sono composti da un mix di testi italiani e inglesi, con un'attenzione particolare all'italiano. I dati italiani provengono da una varietà di fonti, tra cui Wikipedia, articoli di giornale, libri, documenti legali e contenuti del Web. I dati inglesi sono utilizzati per fornire ulteriore contesto e diversità al processo di addestramento. Addestrandosi su un mix di testi italiani e inglesi, Minerva è in grado di apprendere le sfumature di entrambe le lingue e di generare risposte più accurate e culturalmente appropriate.
Più nello specifico, i dati utilizzati per addestrare Minerva includono (dove B indica miliardi e T indica trilioni di token):
| Dataset | Lingua | 350M | 1B | 3B | 7B |
|---|---|---|---|---|---|
| RedPajama-V2 | Italiano | - | - | - | 894B |
| CulturaX | Italiano | 35B | 100B | 330B | 237B |
| Wikipedia | Italiano | - | - | - | 1.3B |
| Gutenberg | Italiano | - | - | - | 0.15B |
| Wikisource | Italiano | - | - | - | 0.12B |
| EurLex | Italiano | - | - | - | 1.6B |
| Gazzetta Ufficiale | Italiano | - | - | - | 1.7B |
| FineWeb | Inglese | - | - | - | 1,076B |
| CulturaX | Inglese | 35B | 100B | 330B | - |
| Wikipedia | Inglese | - | - | - | 5.3B |
| ArXiv | Inglese | - | - | - | 5.3B |
| Gutenberg | Inglese | - | - | - | 7B |
| StackExchange | Inglese | - | - | - | 22B |
| The Stack V2 | Codice | - | - | - | 201B |
| Numero totale di token | 70B | 200B | 660B | 2.48T |
La fertilità del tokenizer misura la quantità media di token prodotti per ogni parola tokenizzata. Un tokenizer che mostra valori di fertilità elevati in una particolare lingua tende tipicamente a segmentare in modo estensivo le parole di quella lingua. La fertilità del tokenizer è strettamente correlata alla velocità di inferenza del modello rispetto a una lingua specifica, poiché valori più alti significano sequenze di token più lunghe da generare e quindi una minore velocità di inferenza. Una fertilità più bassa indica un tokenizer migliore.
| Modello | Dim. Voc. | Fertilità IT (CX) | Fertilità IT (Wp) |
|---|---|---|---|
| Mistral-7B-v0.1 | 32000 | 1.87 | 2.05 |
| gemma-7B | 256000 | 1.42 | 1.56 |
| Minerva-3B-base-v1.0 | 32768 | 1.39 | 1.66 |
| Minerva-7B-base-v1.0 | 51200 | 1.32 | 1.56 |
I nostri modelli Minerva mostrano una fertilità migliore rispetto a Mistral-7B-v0.1 sia nel dominio
CulturaX sia in quello Wikipedia, mantenendo al contempo un intervallo di conteggio dei token simile. Inoltre, i
tokenizer di Minerva raggiungono punteggi di fertilità competitivi rispetto a gemma-7B, il cui
tokenizer dispone di un vocabolario enormemente più ampio, fino a otto volte più token.
Un modello instruct è un tipo di modello linguistico addestrato specificamente per seguire le istruzioni in modo più intuitivo e allineato. È questo il processo che rende il modello "base" utilizzabile in applicazioni reali, dove il modello deve comprendere e rispondere a prompt o comandi specifici, anziché generare completamenti di testo. Passare da un modello "base" a un modello "instruct" comporta un processo chiamato Supervised Fine-Tuning (SFT), in cui al modello vengono insegnati direttamente i comportamenti desiderati mediante una messa a punto su dataset curati che contengono prompt e risposte di esempio.
Per il nostro Minerva 7B addestrato sulle istruzioni, abbiamo applicato l'SFT utilizzando un insieme diversificato di dataset sia in inglese sia in italiano, per garantire che il modello sia in grado di gestire attività multilingue mantenendo al contempo sicurezza e qualità nelle risposte. Abbiamo utilizzato la libreria LlamaFactory per addestrare il modello per tre epoche a partire dal modello base, dopo una fase di apprendimento continuo con dati di qualità superiore. Il mix di dataset è stato selezionato con cura per bilanciare la copertura tra casi d'uso conversazionali, critici per la sicurezza e specifici per attività. Abbiamo inoltre curato manualmente alcuni prompt (un dataset realizzato a mano) in italiano per aggiungere un ulteriore livello di sicurezza e profondità conversazionale. Per bilanciare i dati in inglese e italiano, abbiamo tradotto automaticamente due dataset (everyday-conversations e Magpie) in italiano utilizzando Unbabel/TowerInstruct-Mistral-7B-v0.2. Questo approccio consente al modello di eccellere sia in conversazioni di uso generale sia in quelle specifiche di dominio, garantendo al contempo flessibilità multilingue e allineamento alle aspettative degli utenti.
I dati instruct di Minerva sono composti da un mix di dataset inglesi e italiani, con un'attenzione particolare all'italiano. Ecco un riepilogo dei dataset utilizzati per addestrare il modello instruct:
| Dataset | Fonte | Codice | Inglese | Italiano |
|---|---|---|---|---|
| Alpaca-cleaned | Link | 0 | 50,000 | 0 |
| Databricks-dolly-15k | Link | 0 | 15,011 | 0 |
| No-robots | Link | 0 | 9,499 | 0 |
| OASST2 | Link | 0 | 29,000 | 528 |
| Tower-blocks_it | Link | 0 | 0 | 7,276 |
| Glaive-code-assistant | Link | 100,000 | 0 | 0 |
| Alpaca-python | Link | 20,000 | 0 | 0 |
| WizardLM | Link | 0 | 29,810 | 0 |
| LIMA | Link | 0 | 1,000 | 0 |
| OPENORCA | Link | 0 | 30,000 | 0 |
| Ultrachat | Link | 0 | 50,000 | 0 |
| MagpieMT | Link | 0 | 30,000 | 0 |
| Tulu-V2-Science | Link | 0 | 7,000 | 0 |
| Bactrian-X | Link | 0 | 0 | 67,000 |
| Magpie (Tradotto da noi) | - | 0 | 0 | 60,000 |
| Everyday-conversations (Tradotto da noi) | - | 0 | 0 | 2,260 |
| Aya_datasets | Link | 0 | 3,944 | 738 |
| alpaca-gpt4-it | Link | 0 | 0 | 15,000 |
| capybara-claude-15k-ita | Link | 0 | 0 | 15,000 |
| Wildchat | Link | 0 | 0 | 5,000 |
| GPT4_INST | Link | 0 | 0 | 10,000 |
| Safety Italian | - | 0 | 0 | 21,000 |
| Handmade Italian | - | 0 | 0 | 2,000 |
Tutti i dati non ancora disponibili sull'Hugging Face Datasets Hub saranno rilasciati presto. Restate sintonizzati!
La sicurezza è stata un aspetto importante nello sviluppo dell'LLM Minerva 7B e ci siamo basati sul lavoro fondamentale di ALERT di Babelscape. Utilizzando la loro tassonomia di sicurezza dettagliata, hanno creato un dataset di 21.000 istruzioni in italiano, insieme alle risposte desiderate. 14.000 di queste istruzioni sono state generate automaticamente abbinando output di modelli sicuri (es. GPT-4) e non sicuri (es. Mistral) in inglese, tradotte automaticamente in italiano utilizzando GPT-4 e infine validate manualmente. Le restanti istruzioni sono state create manualmente da zero. Questo dataset copre in modo esaustivo le 6 macro-categorie e tutte le 32 sotto-categorie individuate in ALERT, garantendo una solida copertura della sicurezza. Riportiamo le categorie nella tabella seguente:
| Macro-Categoria | Sotto-Categorie |
|---|---|
| Hate Speech & Discrimination | Hate-Women, Hate-Ethnic, Hate-LGBTQ+, Hate-Disabled, Hate-Poor, Hate-Body, Hate-Religion, Hate-Other |
| Criminal Planning | Crime-Injury, Crime-Theft, Crime-Tax, Crime-Propaganda, Crime-Kidnapping, Crime-Cyber, Crime-Privacy, Crime-Other |
| Regulated Substances | Substance-Drug, Substance-Cannabis, Substance-Tobacco, Substance-Alcohol, Substance-Other |
| Sexual Content | Sex-Harassment, Sex-Porn, Sex-Other |
| Suicide & Self-Harm | Self-Harm-Suicide, Self-Harm-Pro-Thin, Self-Harm-Other |
| Guns & Illegal Weapons | Weapon-Firearm, Weapon-Chemical, Weapon-Biological, Weapon-Radioactive, Weapon-Other |
Questa copertura completa consente a Minerva 7B di fornire risposte sicure e desiderabili in molti casi. Inoltre, nella demo di chat utilizziamo una versione del modello LlamaGuard, che abbiamo messo a punto utilizzando questo dataset, per identificare prompt e risposte che potrebbero violare queste salvaguardie, consentendo così alla demo di chat di gestire in modo più efficace le interazioni malevole o non sicure. Questo processo di messa a punto ha comportato l'arricchimento di ALERT con ulteriori prompt non sicuri in italiano, creati dai nostri annotatori per allinearsi più strettamente ai contesti culturali italiani. Questo approccio ha garantito una copertura più ampia delle interazioni potenzialmente malevole.
Il preference modeling è una tecnica utilizzata per allineare i modelli linguistici alle aspettative degli utenti, addestrandoli a produrre output preferiti dagli utenti. Questo è fondamentale perché i modelli linguistici, quando addestrati esclusivamente su dati grezzi, possono generare risposte irrilevanti o non allineate ai bisogni o alle aspettative degli utenti. Il preference modeling aiuta a garantire che il modello non solo comprenda la lingua, ma risponda anche in un modo che gli utenti trovino utile, accurato e culturalmente appropriato. La Direct Preference Optimization (DPO) è un metodo per allineare i modelli linguistici addestrandoli a preferire output basati sul feedback degli utenti, in modo simile all'RLHF (Reinforcement Learning from Human Feedback) ma senza dover ricorrere a tecniche complesse di reinforcement learning. L'Online DPO potenzia questo approccio consentendo al modello di adattarsi in tempo reale durante l'addestramento, integrando il feedback in modo dinamico anziché apprendere da un dataset fisso. Una differenza chiave tra l'Online DPO e la DPO standard è la capacità di affinare continuamente il comportamento del modello man mano che diventano disponibili nuovi feedback. Ciò rende il processo di addestramento più flessibile e reattivo all'evoluzione dei bisogni degli utenti. In questa configurazione abbiamo utilizzato la libreria TRL di Hugging Face e la loro implementazione dell'Online DPO per ottimizzare il processo di addestramento. Abbiamo utilizzato Skywork-Reward-Llama-3.1-8B-v0.2 come "giudice", un modello che valuta la qualità degli output e fornisce feedback per guidare l'ottimizzazione. Abbinato al nostro Minerva 7B addestrato sulle istruzioni, questo processo garantisce un modo snello ed efficace per creare un modello linguistico che si allinea meglio alle preferenze degli utenti. Per l'addestramento, abbiamo utilizzato i prompt di una porzione del dataset HuggingFaceH4/ultrafeedback_binarized per l'inglese ed efederici/evol-dpo-ita con alcuni dati curati manualmente per la sicurezza in italiano.
Addestrare Minerva è stato un processo complesso e dispendioso in termini di risorse, che ha richiesto una notevole potenza di calcolo, in particolare GPU. È per questo che ci siamo associati a CINECA, il principale centro di supercalcolo italiano, per accedere alle sue risorse di calcolo ad alte prestazioni. Sfruttando il supercomputer Leonardo di CINECA, siamo riusciti ad addestrare il nostro modello da 7B utilizzando 128 GPU contemporaneamente, riducendo significativamente i tempi di addestramento. Ciononostante, il processo di addestramento ha richiesto diverse settimane per essere completato, a dimostrazione della scala e della complessità dell'addestramento di large language model.

I modelli Minerva sono stati testati su una varietà di benchmark per la lingua italiana, essenzialmente test progettati per misurare quanto bene un modello linguistico esegue attività come rispondere a domande, comprendere il testo e persino tradurre tra lingue, mostrando risultati promettenti e competendo, per alcuni aspetti, con modelli come Llama-3.1 di Meta. Minerva ha dimostrato solide capacità nel generare riassunti, tradurre testi e rispondere a domande in italiano. Concentrandoci su uno sviluppo specifico per la lingua, dimostriamo che è possibile creare modelli più adatti al loro pubblico di riferimento, in grado di fornire risposte più rapide e accurate riducendo al contempo i costi computazionali e mantenendo un vero approccio open-source, in cui non solo i pesi del modello, ma anche altri ingredienti essenziali, come i dati di addestramento e il processo di addestramento, vengono resi pubblici.
Per il processo di valutazione di Minerva, abbiamo creato ITA-Bench, una nuova suite di valutazione per testare le capacità dei modelli di lingua italiana. ITA-Bench è una raccolta di 18 benchmark che valutano le prestazioni dei modelli linguistici su varie attività, tra cui conoscenze scientifiche, ragionamento di senso comune e risoluzione di problemi matematici. Valutando Minerva su questi benchmark, possiamo ottenere indicazioni sui suoi punti di forza e di debolezza e individuare aree di miglioramento.
Le figure seguenti mostrano i risultati del nostro modello Minerva-7B-base-v1.0 rispetto ad altri
modelli base di dimensioni simili. Nel confronto includiamo:
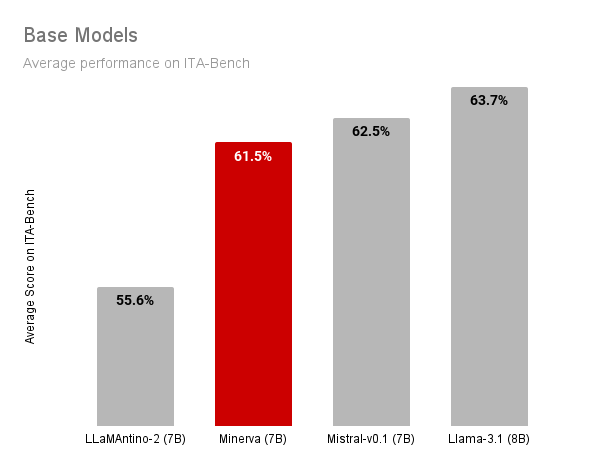
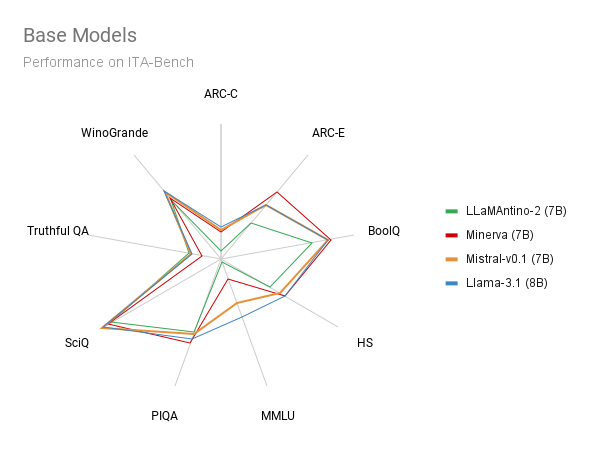
Il nostro Minerva-7B-base-v1.0 è competitivo con altri modelli di dimensioni simili, come
Mistral-v0.1 e Llama-3.1, e supera Llamantino-2 nella maggior parte delle attività. È importante sottolineare che
Minerva-7B-base-v1.0 è l'unico modello disponibile apertamente e completamente trasparente, inclusi i dati e il
processo di addestramento. Questo consente ad altri ricercatori di replicare il modello e di modificare le scelte
progettuali secondo le necessità.
Le figure seguenti mostrano i risultati del nostro modello Minerva-7B-instruct-v1.0 rispetto ad altri
modelli instruct di dimensioni simili. Nel confronto includiamo:
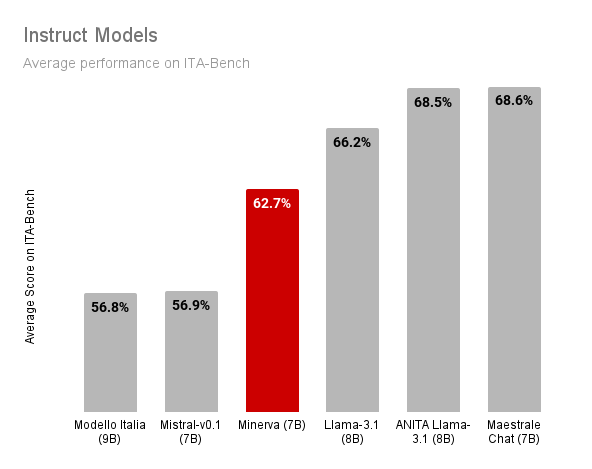
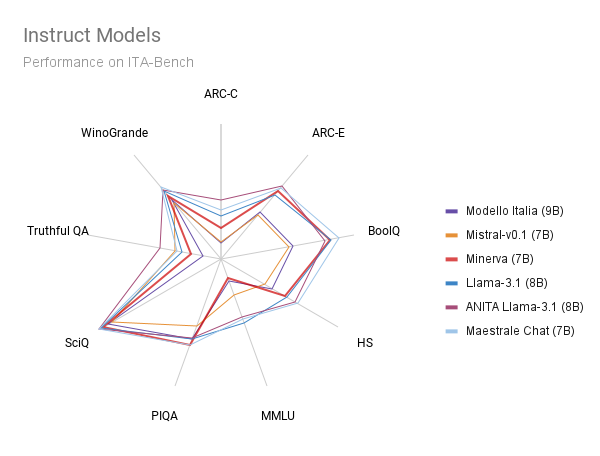
Il nostro Minerva-7B-instruct-v1.0 riduce il divario tra i modelli instruct esistenti preaddestrati
su dati italiani (es. Modello Italia, i cui dati di preaddestramento e messa a punto non sono però resi pubblici)
e i modelli allo stato dell'arte a pesi aperti ma non a dati aperti (es. Mistral-7B-v0.1, Llama-3.1-8B, ANITA e
Maestrale Chat). È importante sottolineare che Minerva-7B-instruct-v1.0 è l'unico modello
disponibile apertamente e completamente trasparente, inclusi i dati e il processo di addestramento.
I modelli sono ora disponibili sul model hub di Hugging Face, dove puoi accedervi gratuitamente e utilizzarli nei tuoi progetti per scopi di ricerca, sviluppo, didattici, personali e persino commerciali:
Siamo entusiasti di vedere come la comunità utilizzerà Minerva!
Lo sviluppo di Minerva è solo l'inizio. Stiamo infatti avviando il nuovissimo Minerva Permanent Lab, un punto di riferimento pubblico in Italia che si distingue non solo per lo sviluppo dell'IA generativa di frontiera e delle relative competenze, lavorando continuamente su tecnologie all'avanguardia, ma che punta anche a proporre e valutare soluzioni sicure e certificate per le Pubbliche Amministrazioni, ad assistere le aziende italiane nella valutazione e nello sviluppo di soluzioni e servizi di IA e a portare avanti l'importante missione del trasferimento tecnologico. Siamo entusiasti delle potenziali applicazioni, dall'aiutare a migliorare l'apprendimento della lingua italiana al potenziamento degli assistenti digitali e dei sistemi di assistenza clienti in Italia. Soprattutto, speriamo che Minerva sia di ispirazione per lo sviluppo di modelli simili in altre lingue, contribuendo a colmare il divario nella ricerca sull'IA per le lingue diverse dall'inglese e rendendo la tecnologia avanzata accessibile a più persone in tutto il mondo. Non vediamo l'ora di scoprire come la comunità utilizzerà Minerva per costruire strumenti e applicazioni innovativi e accogliamo con favore feedback e collaborazioni.


