You can also check out:
- Our Minerva paper for a technical overview our large language models.
- Our ITA-Bench paper for a technical overview of ITA-Bench, our evaluation suite for Italian LLMs.
Large Language Models (LLMs) are revolutionizing our interaction with technology. These models excel at tasks such as summarizing news, translating text, and providing answers in a natural, conversational manner. However, the majority of LLMs are predominantly trained in English, which means other languages, such as Italian, often get less attention. This is where Minerva comes in: a family of LLMs specifically trained entirely from scratch also on Italian texts.
Minerva stands out as a different project, the first initiative to develop LLMs mainly for the Italian language, independent of pre-existing English-trained models. Unlike other models that adapt an English foundation to accommodate Italian, we designed Minerva to have Italian as its core focus from the very beginning. This approach enabled us to tailor our models to the specific features of the Italian language, including its rich vocabulary, complex syntax, and cultural subtleties, areas where English-centric models often fall short.
You can also check out:
It is important to also understand the limitations of our Minerva models. While they are powerful and versatile, they are far from perfect. They may still exhibit biases, generate incorrect or inappropriate responses, or struggle with certain tasks. We are continuously working to improve Minerva and address these challenges, but it is essential to use these models responsibly and critically evaluate their outputs.
It is important to note that Minerva is a research project and is based on available, documented sources. The models do not always provide perfect answers and may sometimes generate incorrect or inappropriate responses. Most importantly, Minerva is primarily a language model and, while we worked on its conversational aspect, any comparisons with commercial chatbots, such as ChatGPT or Claude, should be taken with caution. These models are trained with a much larger set of undocumented data and have hundreds of billions of parameters.
Most LLMs are trained mainly on English texts, which naturally leads these models towards English-centric biases, and this impacts their performance when handling other languages. The vocabulary, i.e., the "words" that these models can use to read an input and generate an output, is optimized for English, meaning that, when they deal with Italian, they often struggle. Indeed, in existing models, Italian words are broken into more pieces than an English word, resulting in increased inference times and reduced fluency in generating natural-sounding Italian text. With Minerva, we overcame these limitations by building a model designed to handle Italian effectively and efficiently. This means the Minerva models generate more natural and culturally accurate text in Italian, providing a significant advantage over existing English-centric LLMs (e.g., Mistral-7B-v0.2), multilingual LLMs (e.g., Llama-3.1), and LLMs adapted from English-centric models (e.g., Anita, Llamantino-2, and Maestrale, among others).
Minerva's importance goes beyond just being a language model for Italian. It also addresses broader issues in Artificial Intelligence research. By focusing on a non-English language, we took a step towards making AI more inclusive and capable of serving diverse communities. The data used to train Minerva is entirely open-source, allowing other researchers and developers to build on our work. This openness contrasts with many of the large language models produced today, where the training data is kept secret (this is not only the case for closed models such as ChatGPT or Claude, but also for open-weight ones, such as all models based on Llama and Mistral). Moreover, Minerva is tailored to minimize biases that might exist in other models trained primarily in English. This is crucial because cultural biases in language models can lead to inaccuracies or inappropriate responses. By creating a model that understands Italian culture and language on a deep level, we are contributing to a more equitable AI landscape.
The Minerva project was not a simple task. We started by training a series of "base" models, ranging from 350 million to 7 billion parameters. A base model is a large language model that has been trained on a diverse range of text data to estimate the probability of a word given its context. This process is often known as pre-training, as the model is simply learning the structure of the language without any specific task in mind. The larger the model, the more parameters it has, which allows it to capture more complex patterns in the data and generate more accurate responses.
To build our base models, we gathered and curated an enormous amount of Italian text to train our models, including sources like Wikipedia, news articles, books, legal documents, and Web content. Our main sources of text for the Web content are RedPajama v2 and CulturaX, two open collections of data obtained from Common Crawl. The total amount of tokens Minerva sees during its training is more than 2,000,000,000,000 (2 trillion) tokens, the equivalent of more than 15 million books, half in Italian and half in English. The goal was to expose the model to a diverse range of language use, from encyclopedic to conversational, capturing the richness of Italian as it is spoken and written in various contexts. We trained four different versions of Minerva, ranging from a smaller model with 350 million parameters to larger ones with 1 billion, 3 billion, and up to 7 billion parameters. Parameters are essentially the building blocks of these models that help them understand and generate language. By creating different versions, we aimed to provide models that are not only powerful but also accessible to various types of users and applications, from those needing a lightweight model to those wanting the most advanced capabilities.
The training data for Minerva is composed of a mix of Italian and English texts, with a focus on Italian. The Italian data comes from a variety of sources, including Wikipedia, news articles, books, legal documents, and Web content. The English data is used to provide additional context and diversity to the training process. By training on a mix of Italian and English texts, Minerva is able to learn the nuances of both languages and generate more accurate and culturally appropriate responses.
More specifically, the data used to train Minerva includes (where B stands for billion and T stands for trillion tokens):
| Dataset | Language | 350M | 1B | 3B | 7B |
|---|---|---|---|---|---|
| RedPajama-V2 | Italian | - | - | - | 894B |
| CulturaX | Italian | 35B | 100B | 330B | 237B |
| Wikipedia | Italian | - | - | - | 1.3B |
| Gutenberg | Italian | - | - | - | 0.15B |
| Wikisource | Italian | - | - | - | 0.12B |
| EurLex | Italian | - | - | - | 1.6B |
| Gazzetta Ufficiale | Italian | - | - | - | 1.7B |
| FineWeb | English | - | - | - | 1,076B |
| CulturaX | English | 35B | 100B | 330B | - |
| Wikipedia | English | - | - | - | 5.3B |
| ArXiv | English | - | - | - | 5.3B |
| Gutenberg | English | - | - | - | 7B |
| StackExchange | English | - | - | - | 22B |
| The Stack V2 | Code | - | - | - | 201B |
| Total # of tokens | 70B | 200B | 660B | 2.48T |
The tokenizer fertility measures the average amount of tokens produced per tokenized word. A tokenizer displaying high fertility values in a particular language typically indicates that it segments words in that language extensively. The tokenizer fertility is strictly correlated with the inference speed of the model with respect to a specific language, as higher values mean longer sequences of tokens to generate and thus lower inference speed. Lower fertility indicate a better tokenizer.
| Model | Voc. Size | Fertility IT (CX) | Fertility IT (Wp) |
|---|---|---|---|
| Mistral-7B-v0.1 | 32000 | 1.87 | 2.05 |
| gemma-7B | 256000 | 1.42 | 1.56 |
| Minerva-3B-base-v1.0 | 32768 | 1.39 | 1.66 |
| Minerva-7B-base-v1.0 | 51200 | 1.32 | 1.56 |
Our Minerva models demonstrate improved fertility compared to Mistral-7B-v0.1 across both the CulturaX and Wikipedia domains, while maintaining a similar token count range. Additionally, Minerva tokenizers achieve competitive fertility scores relative to gemma-7B, whose tokenizer features a vastly larger vocabulary—up to eight times more tokens.
An instruct model is a type of language model that has been specifically trained to follow instructions in a more user-friendly and aligned manner. This is the process that makes the "base" model usable in real-world applications, where the model needs to understand and respond to specific prompts or commands, rather than generating text completions. Going from a "base" model to an "instruct" model involves a process called Supervised Fine-Tuning (SFT), where the model is directly taught desired behaviors by fine-tuning it on curated datasets that contain example prompts and responses.
For our instruction-tuned Minerva 7B, we applied SFT using a diverse set of datasets in both English and Italian to ensure the model is capable of handling multilingual tasks while maintaining safety and quality in responses. We used the LlamaFactory library to train the model for three epochs on top of the base model, after a continual learning step with higher quality data. The mix of datasets was carefully selected to balance coverage across conversational, safety-critical, and task-specific use cases. We also manually curated some prompts (a handcrafted dataset) in Italian to add an extra layer of safety and conversational depth. To balance the data in English and Italian, we automatically translated two datasets (everyday-conversations and Magpie) using Unbabel/TowerInstruct-Mistral-7B-v0.2 to Italian. This approach allows the model to excel in both general-purpose and domain-specific conversations, all while ensuring multilingual flexibility and alignment with user expectations.
The instruct data for Minerva is composed of a mix of English and Italian datasets, with a focus on Italian. Here is a summary of the datasets used to train the instruct model:
| Dataset | Source | Code | English | Italian |
|---|---|---|---|---|
| Alpaca-cleaned | Link | 0 | 50,000 | 0 |
| Databricks-dolly-15k | Link | 0 | 15,011 | 0 |
| No-robots | Link | 0 | 9,499 | 0 |
| OASST2 | Link | 0 | 29,000 | 528 |
| Tower-blocks_it | Link | 0 | 0 | 7,276 |
| Glaive-code-assistant | Link | 100,000 | 0 | 0 |
| Alpaca-python | Link | 20,000 | 0 | 0 |
| WizardLM | Link | 0 | 29,810 | 0 |
| LIMA | Link | 0 | 1,000 | 0 |
| OPENORCA | Link | 0 | 30,000 | 0 |
| Ultrachat | Link | 0 | 50,000 | 0 |
| MagpieMT | Link | 0 | 30,000 | 0 |
| Tulu-V2-Science | Link | 0 | 7,000 | 0 |
| Bactrian-X | Link | 0 | 0 | 67,000 |
| Magpie (Translated by us) | - | 0 | 0 | 60,000 |
| Everyday-conversations (Translated by us) | - | 0 | 0 | 2,260 |
| Aya_datasets | Link | 0 | 3,944 | 738 |
| alpaca-gpt4-it | Link | 0 | 0 | 15,000 |
| capybara-claude-15k-ita | Link | 0 | 0 | 15,000 |
| Wildchat | Link | 0 | 0 | 5,000 |
| GPT4_INST | Link | 0 | 0 | 10,000 |
| Safety Italian | - | 0 | 0 | 21,000 |
| Handmade Italian | - | 0 | 0 | 2,000 |
All the data that is not yet available on the Hugging Face Datasets Hub will be released soon. Stay tuned!
Safety was an important aspect in the development of the Minerva 7B LLM and we build on top of the foundational work of ALERT by Babelscape. Using their fine-grained safety taxonomy, they created a dataset of 21,000 instructions in Italian, along with their desired answers. 14,000 of these instructions have been automatically generated by pairing safe (e.g., GPT-4) and unsafe (e.g., Mistral) model outputs in English, automatically translated into Italian using GPT-4, and finally manually validated. The remaining instructions have been manually created from scratch. This dataset comprehensively covers the 6 macro-categories and all 32 sub-categories identified in ALERT, ensuring robust safety coverage. We provide the categories in the table below:
| Macro-Category | Sub-Categories |
|---|---|
| Hate Speech & Discrimination | Hate-Women, Hate-Ethnic, Hate-LGBTQ+, Hate-Disabled, Hate-Poor, Hate-Body, Hate-Religion, Hate-Other |
| Criminal Planning | Crime-Injury, Crime-Theft, Crime-Tax, Crime-Propaganda, Crime-Kidnapping, Crime-Cyber, Crime-Privacy, Crime-Other |
| Regulated Substances | Substance-Drug, Substance-Cannabis, Substance-Tobacco, Substance-Alcohol, Substance-Other |
| Sexual Content | Sex-Harassment, Sex-Porn, Sex-Other |
| Suicide & Self-Harm | Self-Harm-Suicide, Self-Harm-Pro-Thin, Self-Harm-Other |
| Guns & Illegal Weapons | Weapon-Firearm, Weapon-Chemical, Weapon-Biological, Weapon-Radioactive, Weapon-Other |
This comprehensive coverage enables Minerva 7B to provide safe and desirable answers in many cases. Additionally, in the chat demo, we use a version of the LlamaGuard model, which we fine-tuned using this dataset, to identify prompts and responses that could breach these safeguards, thereby allowing the chat demo to handle malicious or unsafe interactions more effectively. This fine-tuning process involved enriching ALERT with additional unsafe prompts in Italian, created by our annotators to align with Italian cultural contexts more closely. This approach ensured broader coverage of potentially malicious interactions.
Preference modeling is a technique used to align language models with user expectations by training them to produce outputs that are preferred by users. This is critical because language models, when trained solely on raw data, may generate responses that are irrelevant or misaligned with user needs or expectations. Preference modeling helps ensure that the model not only understands the language but also responds in a way that users find helpful, accurate, and culturally appropriate. Direct Preference Optimization (DPO) is a method for aligning language models by training them to prefer outputs based on user feedback, similar to RLHF (Reinforcement Learning from Human Feedback) but without relying on complex reinforcement learning techniques. Online DPO enhances this by allowing the model to adapt in real time during training, integrating feedback dynamically rather than learning from a fixed dataset. A key difference between Online DPO and standard DPO is the ability to continuously refine the model’s behavior as new feedback becomes available. This makes the training process more flexible and responsive to evolving user needs. In this setup, we used the Hugging Face TRL library and their implementation of Online DPO to streamline the training process. We used Skywork-Reward-Llama-3.1-8B-v0.2 as the “judge,” a model that evaluates the quality of outputs and provides feedback to guide optimization. Paired with our instruction-tuned Minerva 7B, this process ensures a streamlined and effective way to create a language model that better aligns with user preferences. For training, we used the prompts from a portion of the HuggingFaceH4/ultrafeedback_binarized dataset for English and efederici/evol-dpo-ita with some manually curated data for safety in Italian.
Training Minerva was a complex and resource-intensive process that required a significant amount of computational power, especially GPUs. This is why we partnered with CINECA, which is the leading Italian supercomputing center, to access their high-performance computing resources. By leveraging CINECA's Leonardo supercomputer, we were able to train our 7B model using 128 GPUs at the same time, significantly reducing the time of training. Even so, the training process took several weeks to complete, demonstrating the scale and complexity of training large language models.

The Minerva models have been tested on a variety of Italian language benchmarks, essentially tests designed to measure how well a language model performs tasks like answering questions, understanding text, and even translating between languages, showing promising results and competing with models, such as Llama-3.1 by Meta in some respects. Minerva has shown strong capabilities in generating summaries, translating texts, and answering questions in Italian. By focusing on language-specific development, we are showing that it is possible to create models that are better suited to their target audience, providing faster and more accurate responses while reducing computational costs and maintaining a true open-source approach, where not only the model weights but also other essential ingredients, such as the training data and the training process, are disclosed.
For the evaluation process of Minerva, we created ITA-Bench, a new evaluation suite to test the capabilities of Italian-speaking models. ITA-Bench is a collection of 18 benchmarks that assess the performance of language models on various tasks, including scientific knowledge, commonsense reasoning, and mathematical problem-solving. By evaluating Minerva on these benchmarks, we can gain insights into its strengths and weaknesses and identify areas for improvement.
The following figures show the results of our Minerva-7B-base-v1.0 model compared to other base models of similar size. In the comparison, we include:
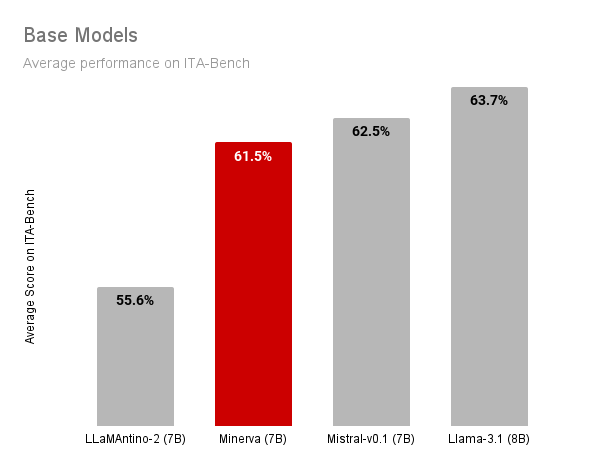
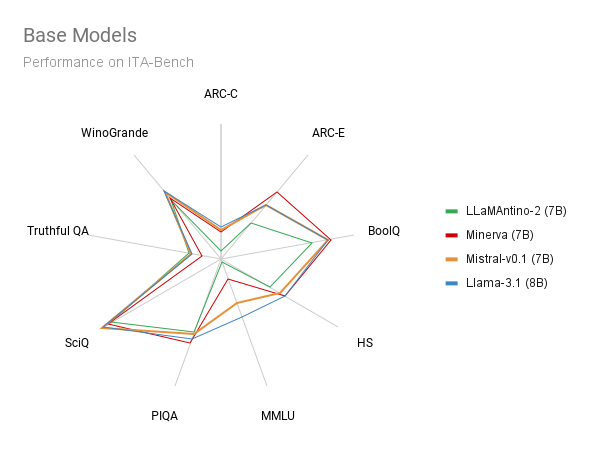
Our Minerva-7B-base-v1.0 is competitive with other models that have similar sizes, such as Mistral-v0.1 and Llama-3.1, and outperforms Llamantino-2 in most tasks. Importantly, Minerva-7B-base-v1.0 is the only model that is openly available and fully disclosed, including the training data and process. This enables other researchers to replicate the model and modify design decisions as needed.
The following figures show the results of our Minerva-7B-instruct-v1.0 model compared to other instruct models of similar size. In the comparison, we include:
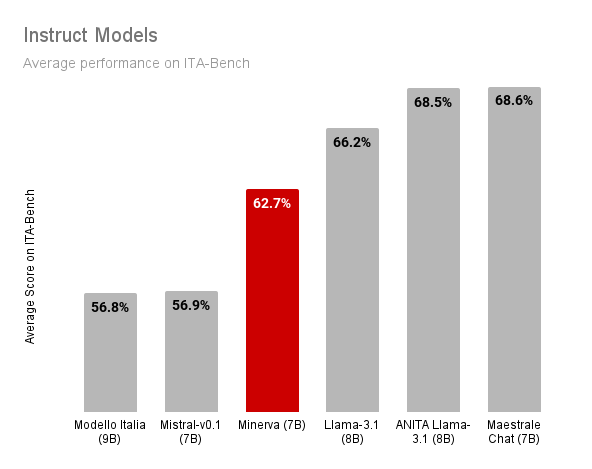
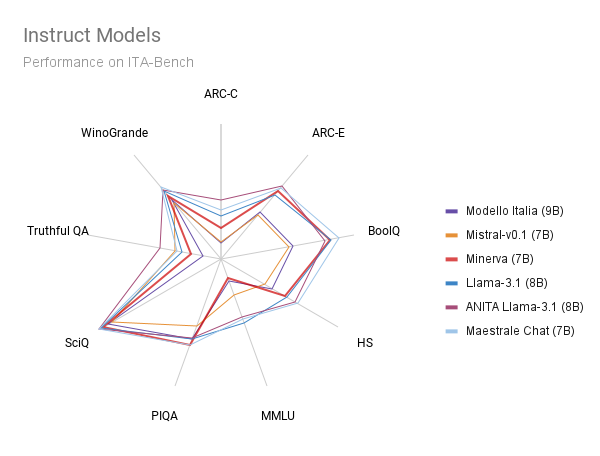
Our Minerva-7B-instruct-v1.0 narrows the gap between existing instruct models pretrained on Italian data (e.g., Modello Italia, whose pretraining and fine-tuning data is not disclosed though) and state-of-the-art open-weight but not open-data models (e.g., Mistral-7B-v0.1, Llama-3.1-8B, ANITA, and Maestrale Chat). Importantly, Minerva-7B-instruct-v1.0 is the only model that is openly available and fully disclosed, including the training data and process.
The models are now available on the Hugging Face model hub, where you can access them for free and use them in your own projects for research, development, educational, personal, and even commercial purposes:
We are excited to see how the community will use Minerva!
The development of Minerva is just the beginning. Indeed, we are starting the brand-new Minerva Permanent Lab, a public reference point in Italy that stands out not only for the development of frontier generative AI and related skills, continuously working on cutting-edge technologies, but also aims to propose and evaluate secure and certified solutions for Public Administrations, assist Italian companies in assessing and developing AI solutions and services, and carry out the important mission of technological transfer. We are excited about the potential applications, from helping improve Italian language learning to enhancing digital assistants and customer service systems in Italy. Most importantly, we hope that Minerva serves as an inspiration for the development of similar models in other languages, helping to close the gap in AI research for non-English languages and making advanced technology accessible to more people around the world. We look forward to seeing how the community uses Minerva to build innovative tools and applications, and we welcome feedback and collaboration.


